Remote video URL
Adam Chin
What does a pixel know?



Artist Statement
I use Artificial Intelligence (AI) algorithms to render images and make art. In practice, I train Machine Learning neural networks on databases of real photography and have them produce new “photographs.” To do this I either have to find a database of photographs to train on, or I have to make a database of photographs.
Asking, “What does a pixel know?,” I treat photography on a metaphorical atomic level, which is the pixel level. Every pixel in a photograph has knowledge about the overall scene that was photographed, and I am trying to tease this information out of the pixel. For example, when you use a Photoshop or Instagram filter to alter a photograph, you are using math to manipulate the information contained in the pixels. By understanding what a pixel knows, I am trying to expand our understanding of how much information is contained in a given photograph. I am exploring what a photograph knows.
Engineering Insight
"What does a pixel know?" At its lowest level, a pixel is data — a set of ones and zeroes. When we view those bits as groups of 16, information emerges — representations of color and luminance. When we step back and look at groups of pixels, structure and features emerge — a nose, an eye, or a freckle. Another step back, and the features combine to form a face. But where does this knowledge reside? Is an arrangement of pixels a face because of their geometry, or because we as viewers impose this meaning on them?
Adam Chin's work challenges us to think more carefully about this question by using algorithmic methods to generate new and unique images from a collection of "real" images. (And what is "real" in this setting?) When we see a new, synthetic image of President Obama, one that's distorted but still clearly recognizable, are we taking in knowledge captured by those pixels, or imposing our own previous understanding and experience? And when we turn to “Man #1,” does that question change? Unlike President Obama, we have never seen this person before, and yet we recognize him, and fill in those missing details. The “Evolution” video presses this point further as we see the algorithm generate progressively more “face-like” images, even though it works without any understanding of what a face is; that knowledge emerges from a combination of the relationship between pixels and our own expectations, hardwired into our visual cortex through millions of years of evolution.
—CHRISTOPHER BROOKS, PH.D., PROFESSOR, DEPARTMENTS OF COMPUTER SCIENCE AND ENGINEERING
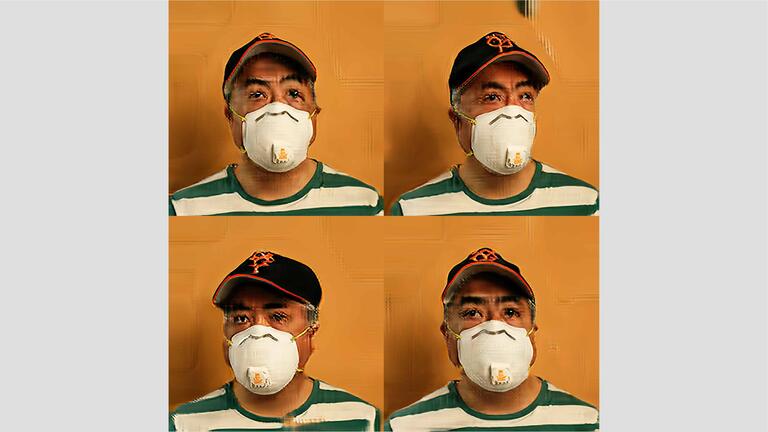
In this SAGAN series, I use the algorithm, Self-Attention Generative Adversarial Networks, to generate portraits. I take a database of roughly 800 photographs and task the neural net with producing an image that looks like one of the 800 photos. The image is not a “Xerox” copy of any one of the 800, but is instead trying to look indistinguishable from the set of 800. If you were to look at all of the images mixed together, the goal is to not be able to tell the difference between the real photographs and the fake.
To me, these portraits are interesting precisely because they fail to reach that goal. The viewer can tell the difference between the real photographs and the fake. Yet on an artistic level, the Machine Learning generated images are still valid portraits of the subjects depicted. For this algorithm, the art is found in the distance between the real and the fake.
Artist Biography
Adam Chin is a fine art photographer who spent a career as a computer graphics artist for TV and film, working on such films as Shrek 2, Madagascar, and How to Train Your Dragon. He studied photography and printmaking under Barry Umstead at RayKo Photo Center in San Francisco. He currently practices using Machine Learning neural networks trained on databases of real photography to render images.